16年間うごいているWebアプリケーションが抱えていた技術的負い目を考察する
技術推進室の浅井です。
技術的負い目とは、世に言う技術的負債のことです。
社内で技術的負債の定義、ことばの表現を考える中で、*「『負債』は優れた比喩表現であるものの、第三者への返済義務がない点で会計上の負債とは異なり、言葉としての問題も多く、不必要な議論を生み出しやすい」*などの指摘があり、代わりの表現として社内の一部で使われている言い回しです。
最近社内のたいへん古いシステム(16年の歴史があります)の技術推進を行う機会があり、たくさんの技術的負い目と向き合いました。
そのような古いシステムの技術的負い目と向き合ったとき、エンジニアはストレスを感じ、ネガティブな感情を抱いてしまいがちです。負い目に苦しめられることで過去のコードや技術的判断に対して不満を言いたくなる気持ちはとてもよくわかりますし、実際に私もたくさん苦しんでたくさん不満を言いました。
ですが技術的負債の文脈でよく言われるとおり、その「負債」も含めてシステムが成り立ち、お金や雇用を生むなどの役目を果たしているのも事実です。またその当時のコードや技術的判断には(チームの未熟さも含めて)悪意ではない相当の理由があったはずです。
エンジニアが本当になすべきことは、不満を言い理想を振りかざすだけではなく、なぜその負い目を抱えたのか、どう対処するべきなのかを考え、負い目も含めたシステムのライフサイクルをコントロールしていくことです。
この記事では私にとって印象深かった10個の技術的負い目を紹介します。
またそれぞれの負い目について考察するとともに、私たちが行っている対処についても説明していきます。
このシステムの歴史、状況、規模感
このシステムは一般ユーザー向けのWebサービスです。
サービスは1999年に開始し、2015年で16年が経過、現在17年目を迎えています。
成長を続けている社内の主力事業のひとつであり、以下のような規模感です。
- エンジニアは事業部署内に9名(加えて、私のような部署外から支援を行うエンジニアや、インフラチームのエンジニアが数名います)
- アプリケーションサーバーに対する一日のリクエスト数は1,500万から2,000万ほど
- メインとなるデータベースの容量は400GBほど
システムの構成、ソースコードのstats
言語: Java
テンプレートエンジン: JSP
アプリケーションサーバー: Tomcat
データベース: 主にOracle
Webサーバー(Apache)があり、その後ろにアプリケーションサーバーがいて、データベースとキャッシュレイヤー(memcached)がある、という一般的な構成です。
ソースコードをGitに移行した際のコミットのstatsが以下のとおりでした。
$ git diff --shortstat initial_commit...import_svn 22464 files changed, 1283878 insertions(+), 6 deletions(-)
128万行ありますが、そのうち80万行ほどはHTML / CSS / JSファイルやHTMLテンプレートファイルが占めています。
またソースコードの静的解析のためにSonarQubeを入れていて、そのデフォルトのルールで解析を行った際のstatsは以下のとおりでした。

ここからは、このシステムにおける具体的な技術的負い目について紹介していきます。
1. 老朽化したシステム
前述の通り16年間うごいているシステムであり、初期開発時(17年前)のソースコードが今でも残っています。利用されていたJDKが2009年にリリースされた6u16というバージョンだったり、10年以上前からアップデートされていないライブラリがあったりもしました。
古いプラットフォームやライブラリは安全とは言えないですし、近代的な機能が備わっていないため開発生産性も低いです。
これだけ古いものになると人材採用にまで影響する大きな負い目になります。
なぜこの負い目を抱えるのか
- プラットフォームやライブラリの更新を誰もケアしていないから
- 何かをアップデートすることの作業コストやリスクが大きすぎるから
どう対処すべきか
- プラットフォームやライブラリの更新に追従していく仕組みを整える
- 更新を検知する仕組みを作ること。
- アップデート作業をバックログとして管理する体制を作ること。
- 変更に対する影響やリスクを最小化する仕組みを整える
- 回帰テストを可能にすること。
- コードベースを小さく保つこと。
このシステムにおける対処
プラットフォームのアップデート
JDKは6から8に上げました。開発環境のアップデートやドキュメントの整備などが大変だったこと以外は大きなトラブルもなく移行出来ました。システム的に変更したのは以下の3点です。
- JVMのメモリパラメータチューニング
- perm領域に関する設定を削除(もう無いので)
- Incremental CMSをやめた(もう非推奨なので)
- 古すぎるAPIやライブラリの呼び出しを削除
com.sun的な非推奨APIの呼び出しを削除(呼び出し元のコードが使われていなかったので削除した)- Apache Xerces / Xalanを削除(XML APIについてはJDKの実装に切り替えた)
Arrays.sortがTimSortになってエラーになった箇所を修正Comparatorの中でlong->intのダウンキャストをしていたため、オーバーフローが発生するケースでcompareTo(x, y)とcompareTo(y, x)の結果に一貫性がない状態だったのを修正
またアップデート時のフローは以下のとおりです。
- 開発環境に新しいJDKを入れて手動でテスト
- 前述の変更点を対応
- 2週間ほどテスト環境で稼働させて問題のないことを確認
- 本番環境に新しいJDKを入れてリリース
JDKのメジャーバージョンについては過去に1.2 -> 1.4 -> 6と上げてきた形跡があり、 今回の8へのアップデートで3回目です。他言語環境と比較してメジャーアップデート時の安全性(後方互換性の高さ)という意味でJava環境は良く出来ていると改めて感じました。
アプリケーションのテストを行う仕組みを整備する必要はありますが、その上で今後はJDKのパッチアップデートも含めて追従していける体制を整えていきます。
ライブラリのアップデート
ライブラリについてはそもそも依存関係管理がなされていませんでした。まずはGradleでのビルド環境を作成し、サーバーに置かれたjarファイルとバイナリ一致するバージョンをMavenリポジトリから探し、管理できるものはGradleで依存関係管理をさせるようにしました。(出自不明なライブラリもいくつかありました)
その後、各ライブラリの利用状況を調べ、アップデート可能なものはアップデートしていっています。
ですが今もすべてを最新に保つことはできていません。現在はWAF (Web Application Firewall) を導入することで安全性を高めつつ、ライブラリのアップデートを進めている、という状況です。
2. 不要なコード
Javaのソースコードは単純行数で49万行、空行とコメント行を除いたLOCで32万行ありました。

これがすべて必要なものであれば良いのですが、事業部署内のエンジニアが肌感覚で言うには「7割は不要なコード」とのことでした。たしかにこのサービスの機能規模から考えると言語やフレームワークを考慮しても(肌感覚で)LOC 10万行程度が妥当に思えます。
なぜこの負い目を抱えるのか
- コードが複雑で密結合すぎて消せないから
- テストコードがなく、テスト方法や仕様が不明確で十分なテストができず、怖くて消せないから
- コストをかけてリスクを負ってまで消す必要性を感じないから
- そもそもコードが不要なのかどうかがわからないから
- なんでもコードを書いて解決しようと思うから
どう対処すべきか
- コードボリュームと品質を視覚化、指標化する
- コードの静的解析を行い、SonarQubeなどで視覚化すること。
- 小さく保つ意志を持って、この指標を意識する人が1人でもいる状態にすること。
- シンプルな設計と実装を心がける
- コードをチームメンバー全員で見れるようにし、変更に対して設計レビュー・コードレビューのプロセスを回していくこと。
- テストできる仕組みを整える
- コア機能の単体テストコードを書くこと。
- 回帰テストとして機能するE2Eテストを自動化すること。
- 密結合を避ける
- 異なる機能間の依存、依存関係の原則に反した設計を避けること。
- いつかコードが不要になる時のことを考える
- コードを読む人に対して、ユーザーに対して、クローラーなどのシステムに対して、状態を適切に伝えようとすること。
- HTTP Status 404を正しく返す、コードや機能の寿命の情報をコメントに記載する、など。
- コードを読む人に対して、ユーザーに対して、クローラーなどのシステムに対して、状態を適切に伝えようとすること。
- 抽象化、汎用化、管理機能化を行う
- おんなじようなコードのコピペを量産しないこと。
- キャンペーンなど、一時的な目的のためのコードを都度書くのではなく、抽象化、汎用化して管理機能化すること。
このシステムにおける対処
不要なコードの削除
実際に頑張ってコードを消してみたところ、全体の128万行のうち30万行ほどが消えました。

Javaのソースコードとしては単純行数で16万行ほど、LOCで10万行ほどが消えました。

7割は無理でしたが3割は消せてだいぶスッキリしました。ただし消すのに2ヶ月近くかかっているのと、消す過程で数回障害を起こしています。テストが人力なのと、それでも十分なテストができないという状況はとてもつらいものでした。
それから半年たって2.6万行ほど増えました。

今後もこのペースで増え続けるのであれば2年ほどで戻ってしまいます。日常的に不要なコードを整理して消していける体制を作るか、あるいはそれを年に1度など定期的に実施していく体制を作る必要があります。
またコード重複率17.9%という異様に高い数字があらわしているのですが、コピペが多いです。コピペしているのは同じような機能の実装なので、これらの汎用化、管理機能化ができればコードボリュームの増大を抑えることができそうです。(サービスとしても運用しやすくなるメリットがあります)
開発プロセスの改善
ほぼすべてのコードをGitHubに移行し、プルリクエストベースのプロセスを適用しました。GitHub flowを簡略化した以下のようなフローです。

プロセスの変更は抵抗も大きく馴染むまでに時間がかかりましたが、1年たった今では事業部署のエンジニアもデザイナーも適応できています。最近ではデザイナー主導でGitHubベースのIssue管理やデザインレビューも行われているなど活用されています。
テストの自動化
開発プロセスの改善と合わせて、JenkinsによるCI環境を作成してプルリクエストとmasterブランチのビルドを行うようにしています。ビルド処理の中では以下のことを行っています。
- gulpによるフロントエンドのビルド
- Javaコードのコンパイル
- Checkstyleによるコーディング規約チェック
- JSPコードのプリコンパイル
- 単体テストの実行

単体テストコードはまだあまり書けていなくて、現在のコードカバレッジは1.7%です。

既存コードの「ロジックが複雑」「仕様が不明」「ソースコードの品質が低い」という問題があり苦労しています。まずはコア機能の単体テストコードを書いて15%程度を目指そうとしている段階です。
また単体テストとは別に、ブラウザ自動操作ツールNightmareとJavascriptのテスティングフレームワークmochaを使ったE2Eテストの仕組みも作っています。CIには含めていませんが、システム上の大きな変更を行う際の回帰テストとして会員登録やログインなど主要機能の動作チェックを行っています。
NightmareでのE2Eテストについては下記のQiitaの記事を参考にさせていただきました。
Nightmare(v1) + mocha ベースに、coffee-scriptでE2Eテストを書く - Qiita
Nightmare(v2) + mocha ベースに、ES6でE2Eテストを書く - Qiita
3. 不要な機能、不要なシステム
不要なコードの話と似ているのですが、機能そのものの必要性が疑われるケース、あるいはシステム構成としてサーバーやミドルウェアの存在理由が定かではないケースがありました。
例えば機能面で言えば、以下のような1日10人も利用することがないコミュニティ機能や

システム面で言えば
- 一日に数回しか呼ばれることのない画像変換サーバー
- 数百MBのログを集計してレコメンドデータを生成するためにうごいているHadoopクラスタ
- 集計結果をExcelに出力するために作られたMongoDBとDjangoとNodejsで作られた集計システム
などがありました。もちろん作られた当初は正当な存在理由や将来に向けての展望があったと思われるのですが、時代やサービスや事業方針や人員体制の変化により「あれ?これって必要なんだっけ・・・?」「なんでこんな設計にしたんだよ!」となってしまったものです。特に技術選定や設計における技術的投資という側面が人員体制の変化に伴って引き継がれず、結果として残ったシステムが負い目として扱われるケースが多いです。
なぜこの負い目を抱えるのか
- 機能のライフサイクルが設計されていないから
- 機能開発の際に運用体制の構築が十分になされていないから
- エンジニアの技術的不満の解消先として、奇抜な構成のサブシステムを生み出してしまうから
- 技術的方針や事業方針があいまいで、人員体制の変化の際に「作られた機能やシステム」だけが取り残されるから
どう対処すべきか
- サービスや機能を作る際にライフサイクルを設計し、クローズする判断の基準やクローズして削除する方法まで考えておく
- システム、仕組み、運用体制の改善を継続的に行う
- エンジニアの技術的満足度を高める
- 技術的チャレンジを求められるような、規模的あるいは技術的難易度がある状態にすること
- 世の中の技術トレンドに対して極端に遅れた状態を認めないこと
- 技術と事業について権限と責任を持った人または組織により、技術的方針と事業方針を一体化したものを明確化、人員体制などの経営判断に反映させていく
このシステムにおける対処
機能の継続可否判断をする体制が無いのでそれを作るところから取り組もうとしています。その場で既存の機能について判断するとともに、今後の開発プロセスの中に機能のライフサイクル設計を盛り込んでいきたいと考えています。
システム面、特に技術選定や設計で生まれてしまう負い目に対しては、それらをコントロールをする仕組みの検討を会社全体で始めています。
4. エラーの常態化
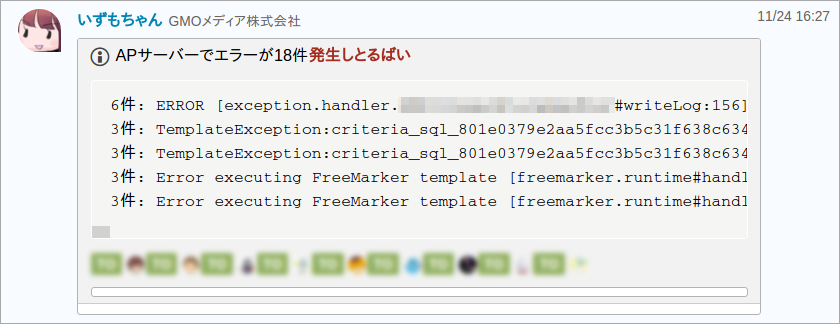
一日のエラーログ件数が4,000件から30,000件ほどあり、一つ一つのエラーについて確認することができない状態でした。
なぜこの負い目を抱えるのか
- 重要ではないものまでエラーログとして出力されるから
- 対応不要なエラーログの発生を放置し続けたから
- エラー通知を見ないで済む仕組みがあったから
どう対処すべきか
- 本当に必要なものだけエラーログを出力する
- ログレベルの明確な定義をすること。
- 入力値のバリデーションをきちんと行うこと。
- エラー通知を鬱陶しくする
- メールのような無視できてしまうものではなく、増えると困る場所に通知すること。
このシステムにおける対処
エラー件数の視覚化と通知
まずはエラーログ件数のグラフ化が行われました。アプリケーションログをfluentd + GrowthForecastで分単位で可視化、というよくあるパターンです。

次にバーストを検知する仕組みが作られました。一定間隔でn件以上エラーログが発生していたら、チーム内のコミュニケーションツールとして使っているChatWorkに通知する、というものです。

(いずもちゃんはChatWork通知用のボットで、博多弁なのは作者の意向です)
エラーの削減
まずは発生しているエラーを分類し、件数の多いものにターゲーットを絞っていきました。

あとは件数の多いものから順に人海戦術で対処していきました。対処の種類は主に以下の3つです。
- エラーそのものの修正(これが必要なケースは少なかった)
- 適切なバリデーションの追加(HTTP Status 4xxで済むものがエラーになっているケースが多かった)
- ログレベルの変更
ログレベルの整備
システム内で明確な定義がなかったため、あらためて策定を行いました。この際に既存コードとの兼ね合いでERRORとWARNの中間に相当するレベルが必要になったため、独自定義して1つ増やしています。
- FATAL
- 即時対応が必要な問題(サービスが停止するようなケース)
- ERROR
- 即時検知して早急な対応が必要な問題
- NUTS
- 正常系ではないがユーザーへの影響を最小限にする対処がなされているか、またはリカバリ手段が存在し、早急な対応は不要か不可能な問題
- WARN
- 正常系ではないがユーザーに影響はなく、早急な対応は不要な問題
- INFO
- 事後調査のために必要となる実行時の状態や情報
- DEBUG
- 開発時のデバッグに必要な情報
ERRORとWARNが大量に出力されている状態で「ERRORとして扱う程ではないエラー」をNUTSとして、ERRORをより緊急性の高い重要な問題のみと定義しました。
ログフォーマットの整備
エラーログを分類したり、調査して対応する過程でログフォーマットの不統一が問題となったため、以下のように定義しました。

これらを行い、3ヶ月ほどかけてエラーを削減していった結果、一日平均50件ほどまで減らすことができました。これでようやく1件ずつ発生都度の通知 + バースト時のサマリ通知、が可能になり、現在はこれを運用しています。
 (ログメッセージ、発生したサーバー、リクエストID、スタックトレースを通知)
(ログメッセージ、発生したサーバー、リクエストID、スタックトレースを通知)
 (1分間に5件以上でサマリしてmention付き通知)
(1分間に5件以上でサマリしてmention付き通知)
 (一日の終わりに総件数を教えてくれる)
(一日の終わりに総件数を教えてくれる)
この通知の鬱陶しさもあってか、エラー件数はその後安定していて、一時的に増えても適切に対処されていっています。
5. ワイルドなバッチ処理
ユーザーのリクエストによって頻繁に更新されるテーブルがあり、そのテーブルを別の場所で動くバッチ処理によってまとめてシングルトランザクションで更新する。というようなワイルドな処理を行うバッチがいくつかあります。
当然バッチ処理によってレコードが長時間ロックされ、ユーザーのリクエストの処理が待たされます。

(0時近くというのはこのサービスのトラフィックが最も多い時間帯で、このバッチはどうしてトラフィックの多い0時近くに実行するのかというと0時ちょうどに実行しないと集計数値がずれてしまう仕組みでした。これはもう設計が良くない)
ロックして待たされるとか、タイムアウトしてエラーになるくらいならまだ良かったです。
最悪の状況では以下の問題が起きていました。
- Tomcatのワーカースレッドの上限が大きすぎて、一部の処理が詰まるとサーバーのキャパシティ以上にスレッドを動かしてしまい
- DB接続プールが先に枯渇して、ロックとは関係ないすべてのDB参照処理が待たされる
- その結果スレッドが溜まり続けてGC処理が追いつかず高負荷でサーバーがダウンする
- トランザクション中のDB接続を強制的にコミットしてクローズする
後者ははじめ意味がわかりませんでしたが、要するにトランザクションの原始性が破壊されていました。
Apache Commons DBCPという接続プールライブラリを使用していたのですが、このライブラリにremoveAbandonedという機能があります。この機能はアプリケーションスレッド内でDB接続を取得した際にクローズ処理(接続プールへの返却)が漏れているケースを想定して、一定時間以上使われているDB接続を強制的にクローズして接続プールに返却する機能です。
このとき実行中のトランザクションが存在した場合にコミットするかロールバックするかの挙動はJDBCの仕様に定義されていなくて実装依存になっています。使っていたOracle JDBCドライバはコミットする仕様でした。これはクローズ処理漏れを前提とすれば適切な仕様に思えます。
その結果、以下のようなコードを実行する際に、2つ目のアップデートで一定時間以上ロックを取得できない状態が続くとトランザクションの途中でコミットされます。
try (Connection conn = pool.borrow()) {
begin(conn);
updateTableA(conn);
updateTableB(conn); // ここで一定時間経過すると updateTableA のみ実行されてコミットされる
updateTableC(conn);
commit(conn);
} catch (Exception e) {
rollback(conn);
}
この機能が有効に設定された状態で前述のようなワイルドなバッチ処理が実行されていたため、データの不整合が発生していました。
別のワイルドさとして、以下のようなものもあります。

これはNewRelicで確認した、アプリケーションサーバー(ユーザーのリクエストを処理しているサーバー)のリクエストログから抜き出したものです。バッチ処理がオンラインで実行されている状態です。30秒間スレッドを掴んでいます。
なぜこの負い目を抱えるのか
- バッチ処理設計時の並行処理やスケールに対する考慮が足りないから
- アーキテクチャ、方式設計に対する理解がないから
- バッチ処理の実装やデプロイに不便さがあるから
どう対処すべきか
- 開発ルール、規約を整える
- バッチ処理はどこに実装するべきか、という大きな粒度から規約に含めていくこと。
- バッチ処理の開発環境とデプロイフローを改善する
- 改善が追いつかず言語ランタイムのバージョンが低いとか、ソースコードが違う種類のソースコードリポジトリにあるとか、手動でビルドしてデプロイするフローだとか、不便さを残さないこと。
このシステムにおける対処
開発ルール、規約を決めるためのルールの作成
チーム内に暗黙に存在するルールやエンジニア個人の考え方もあるため、ルールや規約を決めて強要していくのではなく、それらを決めるためのルール作りを行いました。

まだ大きな粒度の規約を盛り込めていませんが、設計・コードレビューの中で「これってどうなの?」という話があった時はプルリクエストベースの合議制で規約を定めていくようにしました。
バッチ処理の開発環境とデプロイフローの改善
Webアプリケーション側の開発環境とデプロイフローの改善が進む中でバッチ処理のそれは取り残されがちでしたが、いろいろと問題を抱えていたため以下のような改善を行いました。
- Webアプリケーションと同様にGitHubへ移行し、プルリクエストベースの開発フローに変更
- AntからGradleでのビルドに変更
- テスト環境でビルドとデプロイを行っていたものを、Jenkinsから行うように変更
- cron設定が管理されていなかったのをGitHub管理しデプロイに含めるように変更
- デプロイに伴ってバッチ処理のログが全て消えてしまう問題を修正
- Java実行時のエラーを検知する仕組みがなかったので追加
バッチ処理に起因するWebアプリケーションの問題を改善
サーバーがダウンしてしまう問題、トランザクションの原始性が破壊されてしまう問題は危険性が高く、かつ徐々に頻度が上がっていたため優先して対応しました。
JVMパラメータ、Tomcatのワーカースレッド数、DB接続プール、Apacheの同時接続数の整合性を取り、十分なパフォーマンスが出て、リクエストのバースト時やDBのロックにより処理が詰まった際にサーバーのダウンが起きないようにチューニングをしました。
- Tomcatのスレッド数とCPUコア数のバランスを取る
CPUコア2つに対して700スレッドだったものを200まで下げました。平常時のアクティブスレッド数が30前後であるため50まで下げたかったのですが、一部の処理がDBのロックにより詰まった際にスレッドが埋まってスループットがゼロになるのを避ける必要があって、これ以上下げることはできませんでした。その代わりCPUコア数を増やす対応をしています。
- Tomcatのスレッドがすべてアクティブな状態であっても許容できるよう、JVMのメモリパラメータを調整する
[before] Full GCによる5秒程度の停止が頻繁に起きる状況でした。(グラフの黒い線がFull GC)
-Xms1536m -Xmx1536m -XX:NewSize=512m -XX:MaxNewSize=512m

[after] Full GCはなくなり、CMSInitiatingOccupancyFraction=50により早めにCMSを動かして余裕をもたせています。(グラフの黄色い縦線がCMSで黄色い横線がCMS-initial-mark時のOldサイズ)
アクティブなスレッドを最大で200も持ってしまうのと、サービスの特性上バースト時のスパイクが大きいためだいぶ大きな数字になっています。
-Xms3456m -Xmx3456m -XX:NewSize=1920m -XX:MaxNewSize=1920m -XX:SurvivorRatio=3 -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=50

これで200スレッド動いてもなんとか耐えられる状態です。
- Tomcatのスレッド数を、DB接続プール数と同じかより少なくする
Tomcatのスレッド数700に対してDB接続プールの上限が115でした。Tomcatのスレッド数を200まで下げたのに合わせて、DB接続プールの上限も200としました。
- Apacheの同時接続数をTomcatのスレッド数に合わせる
これはTomcatがリクエストをキューイングするため不要なはずでしたが、Tomcatのスレッド数を700から200まで下げたのにあわせて、ApacheのMaxClients / ServerLimitも下げました。(Apacheは静的コンテンツも返しますが、CDNがあるのでほぼTomcatへのリクエストが占める前提)
これらのチューニングの結果、アプリケーションサーバーがダウンしたり手動で再起動が必要な状態に陥ることはなくなりました。
ワイルドなバッチや、ワイルドな手作業で激しいDBロックを発生させたり、ワイルドなリリースでDBサーバーをダウンさたり、といった事件はありましたが、それにより処理を詰まらせて応答速度が悪化することはあっても、アプリケーションサーバーは止めずに自然回復できています。
- DB接続プールの修正
removeAbandonedという機能の使用をやめることはできませんでした。DB接続プールの操作はフレームワークレイヤで解決されていなくて、すべてのDBアクセス処理にコーディングされていたため、クローズ処理漏れが頻繁に発生していたからです。
そのため別の方法でクローズ処理漏れの検知と回収処理を実装しました。(DIコンテナもない環境なのでDataSourceクラスをラップして、Connectionオブジェクトの動的プロキシを作ってopen/closeをフックさせる仕組み)
このときついでにDB接続プールライブラリをHikariCPというものに置き換えました。元のApache Commons DBCPがすごく古いというのもありますが、これだけでTomcatの平均応答速度が10msec下がりCPU負荷が2割減という劇的な効果がありました。
現状でできたのはここまでで、肝心のバッチ処理の修正はできていませんし、Webアプリケーション側はJDK8に上げたのにバッチ処理はJDK6のままだったりします。テストが十分に行えないバッチが多くて、この問題の解決には時間がかかりそうです。
6. 危険なデプロイメント
デプロイによってシステムが一時的に壊れる仕組みでした。お祈りが足りないとこうなります。

(デプロイ内容に問題があるわけではなくて、デプロイ処理そのものに問題がある状態)
運が良いとエラーが出ないこともありましたが、以下のようなことが頻繁に起きる状態でした。
- セッションが切断される
- 一時的に一部の処理がエラーになる
- 一時的に502を返す
- 一時的に高負荷になり応答速度が悪化する
また、Subversionのtrunkのみで運用しつつコミットしないとテスト環境にデプロイできないという環境だったため、十分にテストがなされていないコードがtrunkに上がっている状況が常でした。
その結果として以下のようなことが起きていました。
- 本番リリースの前に関係者の了解を取る必要があった(リリース内容の了解ではなく「今実行して大丈夫か」という了解)
- 確認しきれずに動かないコードが本番にリリースされることがあった
- リリースを行うこと自体が危険、かつユーザーに悪影響があるのでリリースの頻度や時間帯に厳しい制限がかかっていた
- リリースの頻度が低くなり、複数の変更がまとまってリリースされることで、障害時のロールバックが難しくなっていた
- リリースが先送りされ、改善スピードが低下していた
なぜこの負い目を抱えるのか
- デプロイに関する問題意識がなかったから(それがあたりまえという認識)
- 技術的難易度が高かったから
どう対処すべきか
- デプロイの仕組みは常に安全で、かつ高速に頻繁に実行できるようにする
- 必要に応じて経験のあるエンジニアの力を借りること。
このシステムにおける対処
デプロイ処理の修正
デプロイ時にエラーが起きてしまう原因は以下のようなものでした。
- ロードバランサーから切り離す前にTomcatを停止している
- Tomcatを起動後、アプリケーションのモジュールがTomcatにデプロイされて応答を返せるようになるより前にトラフィックを受けてしまっている
- ロードバランサーがスロースタートをしていないので急激なトラフィックにTomcatが耐えられなくなっている
まずTomcatを停止する前に、ロードバランサー(ここではApacheのmod_proxy_balancer)にワーカーを切り離させるようにしました。これでデプロイ時に502を返してしまう問題はなくなりました。
次にTomcatの起動後にアプリケーションがリクエストを処理できるようになるまで待機する処理を入れました。アプリケーションのトップページが200を返すようになるまで待機したあと、さらに負荷テストツールを使ってウォームアップ処理を入れています。DB接続プールやスレッドプールの初期化をさせたり、JVMの自己最適化を行わせたり、JSPコンパイル、クラスのロードを先に行っておくことが目的です。これでデプロイ後の高負荷や応答速度の悪化がなくなりました。
デプロイに関する成約を減らす
安全面では、まずtrunkのみでの運用をやめ、プルリクエストベースの開発プロセスとしたことでテストもレビューもなされていないコードがデプロイされる可能性をなくしました。GitHubのmasterにマージされたものはいつデプロイしても問題ない、という前提を作っています。
また、本番デプロイ時に自動的にリハーサル環境にデプロイして、正常に動作しない場合はデプロイを中止するようにしています。

(ぼかされている画像はJSP本番デプロイ時に表示される武蔵丸です)
とはいえ単体テストが十分にあるわけではないので、ここでの正常に動作しているかの確認は以下のような処理です。
- ひととおりのURLにリクエストを送る(curlで)
- 想定していないHTTP Statusが返ってきたらNG
- エラーログが出力されたらNG
- BODYの閉じタグがレンダリングされていなかったらNG
これだけの確認でも十分に効果的で、すべてのエラーをカバーできるわけではありませんが、致命的なデプロイ時のトラブルを何度も防ぐことができています。
これらの対応の結果、リリースに関する制約を最小限にすることができました。現在の必須の制約は以下のとおりです。
- 事前に十分な動作確認を行うこと
- リリース内容をChatWorkで共有すること
- リリース後の確認まで含めて作業できる時間があること(所要時間は20分ほど)
- そのリリースに関して「リリースする本人以外誰も何も知らない」という状態を作らないこと
7. 雑な共通化
共通化目的で作られた**-common.jarという名前のライブラリが2つありました。
ですがいずれも出自が不明で、だれも正体を知りませんでした。ましてやソースコードがなく、まさにブラックボックスです。そのくせすごくコアなところで動いています。
そのため
- エラー調査でここに行き着いた場合はなにかワークアラウンドを探しに行く
- 静的に参照されていて拡張が難しいため、変更のために実行時のバイトコード操作が行われる
など、この共通化ライブラリは聖域となっていました。
なぜこの負い目を抱えるのか
- ビルド、デプロイ、バージョニングが定まっていないまま共通化してしまったから
- 十分に抽象化されていなくて、拡張に対して開かれていないから
どう対処すべきか
- 共通化モジュールを作るのであれば入念な設計を行い、それなりのものを作る
- 社内のMavenリポジトリのようなデプロイ先リポジトリを用意すること。
- JavadocなどのAPIドキュメントを書いて配布物に含めること。
- MavenやGradleのようなビルドシステムを使って、配布物にソースコードの所在などのモジュールの定義情報を含めること。
- モジュールのメンテナが不在にならないように管理する
このシステムにおける対処
リバースして生成したコードに置き換えるか、代替コードを書いて置き換えるか、が考えられますが、危険度が高くて実施できていません。ここは諦めつつあります。
8. 不適切な並行性制御
Webアプリケーションとして行うべき並行性制御が十分になされていないという問題がありました。
例えば以下のようなコード。
// hogeが未登録であれば登録する
hoge = dao.getHoge(userId, hogeType);
if (hoge == null) {
dao.insertHoge(userId, hogeType);
}
排他制御がないので別のスレッドやサーバーで同じ処理がなされた場合にはinsertHogeが2回実行される可能性があります。データベースの一意制約エラーにより防がれるケースもありますが、サロゲートキーが使われ、かつユニークキーもなく二重でinsertされるケースもありました。
あるいは以下のようなコード。
// 10回まで実行可能
count = dao.getCount();
if (count <= 10) {
doSomething();
dao.update(count + 1);
}
カウンタの取得とカウントアップの処理がアトミックではないため、並行処理環境では10回じゃなくて11回以上実行できてしまうパターンです。
そのほかにも、ライブラリのスレッドセーフではないクラスを複数スレッドから利用していたり、複数レコードの更新を行うトランザクションに順序の整合性がなくてデッドロックを起こしていたり、JVM上でインメモリキャッシュしているCollectionをiterateする処理と破壊する処理が存在してConcurrentModificationExceptionが出ていたり、など、並行性制御における問題が散見されていました。
なぜこの負い目を抱えるのか
- 並行処理を十分に考慮せずに作られてしまったから
- 並行処理における問題を追跡できるエンジニアがいなかったから
どう対処すべきか
- 優秀なエンジニアを雇う
- ある程度の知識・経験があるサーバーサイドのWebアプリケーションエンジニアを参加させること。
- 並行性制御についてきちんと学ぶ、教育をする
- チームメンバーが基礎的な知識を持ったうえでコーディングに臨める状態にすること。
- コードレビューを通じて問題点を丁寧に伝えていくこと。
このシステムにおける対処
システムとして直せるものについては直していっています。
ですが、これらの問題は頻繁に発生するものではなく、かつ再現性が低くて原因の特定や修正が困難なものもあり、すべてを検知することも直すこともできていません。
教育面では全社的な取り組みとして「エンジニア技術力底上げプログラム」というものがあり、この中でWebアプリケーションにおける並行性制御についても取り上げ、教育を行いました。
ただ短期的な教育だけでは十分ではなくて、業務上で各自が書いたコードについてレビューを行い、問題のあるコードを指摘して説明していくことが多いです。
9. 認識されていない単一障害点
認識されて、コントロールされている単一障害点(以下SPOFと記載)についてはまだ良いのですが、「冗長化されていてSPOFではない」という認識でありながら実際は1台ダウンするとサービスが止まる、というようなSPOFがありました。具体的には
- Webサーバーが1台でも停止するとWebサーバー上のmemcachedに接続できなくなりアプリケーションサーバーが全滅する
- アプリケーションサーバーが2台停止するとWebサーバーのApacheがクラッシュして全滅する
というものです。アプリケーションサーバーとWebサーバーはそれなりの台数で冗長化されているのですが、結局1台か2台停止しただけですべてが停止してしまう状況でした。
memcachedに接続できなくてアプリケーションが動かなくなってしまうのは、memcachedに接続するためのJavaのライブラリに問題があって障害時にクラスタからの切り離しができていなかったためでした。
Apacheがクラッシュしてしまうのは、ロードバランサーとして使っているmod_proxy_balancerがTomcatのセッションクラスタリングを前提としてスティッキーセッションかつフェイルオーバー先のサーバーを指定する構成になっていて、そのフェイルオーバー先のサーバーも同時にダウンしているとApacheのプロセスがセグフォを起こしてしまうという問題でした。
おそらくシステムを作成した時点ではSPOFではなかったはずなのですが、後の拡張やサーバー環境の変化、使われ方の変化によりSPOFに昇格したのではないかと思われます。
なぜこの負い目を抱えるのか
- システム構成の変更時に障害テストが行われていないから
- ライブラリやミドルウェアの選定が不十分だから
どう対処すべきか
- 障害テストを実施する
- まずは障害テストが行えるだけのテスト環境を準備すること。
- 定期的、またはシステム構成の変更時にそれを実施できるようにすること。
- ライブラリやミドルウェアの追加を行う場合はきちんと選定を行う
- 機能要件を満たしているだけで良しとするのではなく、ドキュメントを読み、テストを行い、性能面や運用面の問題なども含めて確認すること。
このシステムにおける対処
まずTomcatのセッションクラスタリングは行われていなかったため、mod_proxy_balancerからの不要なフェイルオーバー先指定は取り除きました。(これだけでApacheがクラッシュする問題は解決されました)
memcachedのライブラリについてはソースコードの都合上影響範囲が大きくてまだ対応出来ていません。が、SPOFであることを認識できているので、メンテナンスのためにmemcachedを停止する場合は事前にクラスタから切り離してリリースを行い、メンテナンス後に元に戻すという運用をすることができています。 認識できていなかった頃は「大丈夫だと思ってmemcachedを停止したらサービスも停止した」という事故があったりもしました。
障害テストについては今でも実施できていません。負荷テストなども含めて大きなシステム変更時の非機能的なテストの手段が整っていないので、引き続き仕組みづくりをしていくところです。
10. 不安定な外部システムへの直接的依存
ここで取り上げた中ではこの負い目が最も困ったものでした。
外部システム連携は一度作られた仕組みを変更するのが容易ではなくコスト面で現実的ではなかったり、また先方のシステムが不安定であったとしても契約で縛られていたり売上やサービス要件の都合上代わりを用意することが難しかったりするため、根本的な対応が行いづらいからです。
加えてこのシステムにはサービスの特性上たくさんの外部システム連携があります。(不正確ですが数十個のシステムに依存しています)
その中である外部システムAPIへのアクセスが突然異常に遅くなるというトラブルがありました。

(ある外部システムAPIの応答速度の推移)
応答速度が速かった頃の前提でオンラインで必要都度アクセスするように作られていたため、引きずられてこちら側のアプリケーションも応答速度が低下して高負荷になりました。

(こちら側のアプリケーションの応答速度の推移)
その後はシステム連携先に改善を要求したり、それでも良くならずに遅いリクエストを大きく切り捨てるようなタイムアウト設定にしたり、エラーが続くときはAPI呼び出しを行わないようにしたり、という対応を行いなんとか安定化させました。(本当は連携の方法を変えるか連携そのものをやめるかして、このAPI呼び出し自体を取り除きたかった)

(外部システムAPIの応答速度をプロットしたもの。赤線の位置でタイムアウトさせる)
この問題は外部システムの疎通の時間をモニタリングする仕組みもなかったため、原因を特定するための調査に時間がかかっています。
なぜこの負い目を抱えるのか
- 外部システムの呼び出しを個別にモニタリングできる仕組みがなかったから
- 外部システムとの連携設計において外部システムを信頼してしまい、エラーケースの考慮が不十分だったから
- 外部システムとの連携を伴う契約において、システム上の懸念が加味されていないから
どう対処すべきか
- 外部システムの呼び出しを個別にモニタリングできるようにする
- NewRelicなどのモニタリングツールを活用すること。
- 外部システムとの連携時はエラーケースを考慮した設計を行う
- 動かない前提でエラーケースの対応と復帰の仕組みを作ること。
- 外部システムとの連携を伴う契約においては可能な限りシステム上のリスクを担保させる
- 応答速度やサービスレベルの規約を契約に含めること。
このシステムにおける対処
NewRelicの導入
社内のほかのシステムでも導入していて実績があったためNewRelicを導入しました。Javaの場合JVMのagentとして動作し、外部システムごとの応答速度なども含めて細かい情報を拾ってくれます。

(問題のあった外部システムAPIの現在の応答時間の推移。当時からNewRelicが入っていれば調査は楽だった)
ただしNewRelicの導入自体にも苦労がありました。一度とりあえず入れてみたら翌朝サーバーがダウンしてしまう事故を起こしています。NewRelicのagentがバイトコード操作を行うために(当時JDK6で)Perm領域を多く消費するため、メモリチューニングが必要でした。またモニタリングのオーバーヘッドも大きく、当時のagentのデフォルトの設定で23%ほどスループットの限界値が下がりました。
システムリソース的にもNewRelic自体の利用料金的にもコストはかかっていますが、それでも得られる情報の価値は大きかったです。
以上が印象深かった技術的負い目です。
それぞれに書いた「どう対処すべきか」をまとめると以下のようになります。
- コード、設計に対する取り組み
- コードボリュームを視覚化、指標化して小さく保つこと
- 密結合を避け、異なる機能間の依存、依存関係の原則に反した設計を避けること
- 抽象化、汎用化、管理機能化を行うこと
- 共通化モジュールを作るのであれば入念な設計を行い、それなりのものを作ること
- 並行性制御についてきちんと学ぶこと
- ライブラリやミドルウェアの追加を行う場合はきちんと選定を行うこと
- 外部システムとの連携時は個別にモニタリングできるようにし、エラーケースを考慮した設計を行うこと
- 開発フロー、仕組みづくりに対する取り組み
- 変更に対する影響やリスクを最小化するため、単体テスト、E2Eテスト、障害テストを実施できる仕組みを用意すること
- 本当に必要なものだけエラーログを出力し、通知を鬱陶しくすること
- デプロイの仕組みは常に安全で、かつ高速に頻繁に実行できるようにすること
- プラットフォームやライブラリの更新に追従していく仕組みを整えること
- コードをチームメンバー全員で見れるようにし、変更に対して設計レビュー・コードレビューのプロセスを回していくこと
- 開発ルール、規約を整えること
- 企画、サービス設計に対する取り組み
- 外部システムとの連携を伴う契約においては可能な限りシステム上のリスクを担保させること
- サービスや機能を作る際にライフサイクルを設計し、クローズする判断の基準やクローズして削除する方法まで考えておくこと
- その他重要な取り組み
- システム改善を継続的に行うこと
- エンジニアの技術的満足度を高めること
- 優秀なエンジニアを雇うこと
- 技術と事業について権限と責任を持った人または組織により、技術的方針と事業方針を一体化したものを明確化、人員体制などの経営判断に反映させていくこと
どれもあたりまえのことなのですが、これらができていない状態で長期間システムが開発・運用され続けるとどうなってしまうのか、という点で16年間うごいているこのシステムからは学ぶことがたくさんあります。
技術的負い目と向き合う
このシステムと事業部署に対する技術推進を行う中で、ここに書いたような様々な技術的負い目と向き合い、やっつけたりやっつけられたりしてきました。 その結果、ここ1年で以下のような成果がありました。(事業部署のメンバーやインフラチームの協力のおかげです!)
- SubversionからGit(Hub)へ移行
- JDK6からJDK8に更新
- プルリクベースでコードレビューを行う開発フローの構築
- テストの仕組み、CI環境の構築
- 祈らなくてもデプロイできる環境の構築
- 管理可能なレベルまでエラーの発生数を削減
- 日常的に起きていた「応答速度の悪化」と「数分程度のシステムダウン」をなくした
長期間積み上げられた技術的負い目は複雑化して根深い問題になっていて、ここに書いたような成果を出すためにはたくさんの地道なステップが必要でした。もちろんそれでも解消できていない負い目も数多くあります。
こういった負い目はシステムのライフサイクルの中で必ず生まれてくるものだとは思いますが、長期間積み上げてはいけません。冒頭にも書きましたが、負い目も含めたシステムのライフサイクルをコントロールしていくべきです。具体的には、負い目を認識した時点でバックログとしてタスク管理を行い、定期的に負い目の棚卸を行っていくべきです。(これだけでずいぶん未来は変わるのだろうな、と今は思っています)
さて気がついたら非常に長い記事になってしまいました。本当はもっと書きたいことがあるのですが今回はこれくらいにしておきます。
この記事が負い目と向き合う皆様のお役に立てれば嬉しいです。
メリークリスマス! (2015/12/25)
追記
この記事を作成している途中で文章に悩んで煮詰まって以下のような記事も書きました。 よろしくどうぞ!
